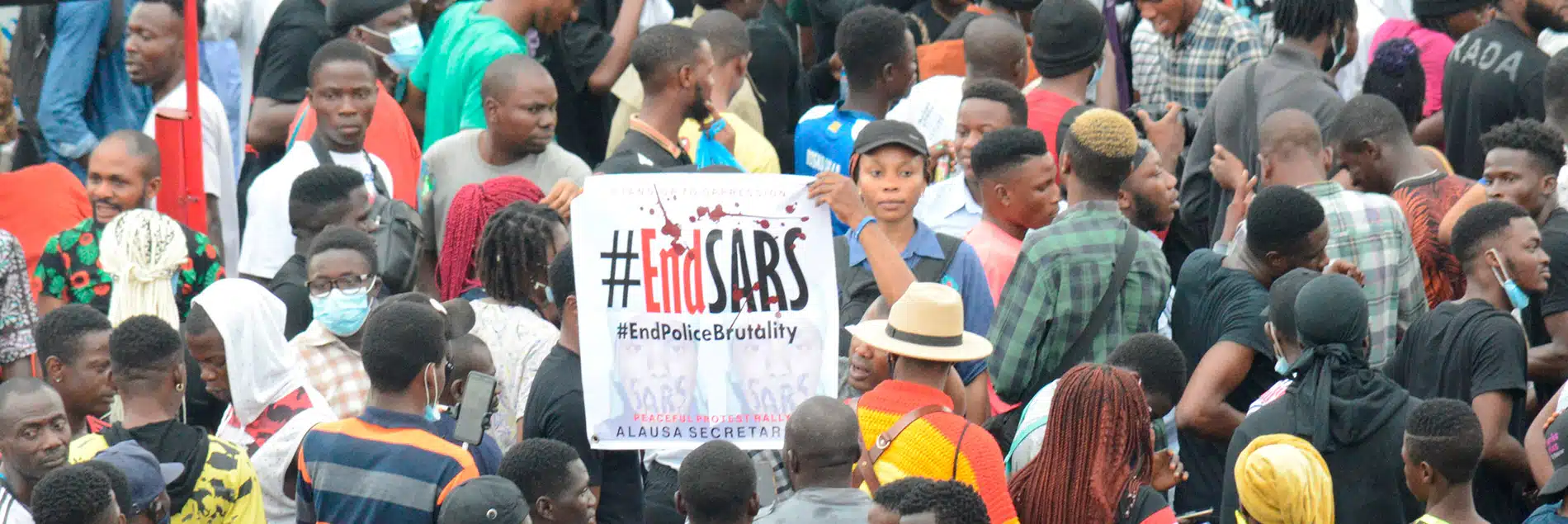










Parece que no se puede detener a la inteligencia artificial, así que la pregunta es: ¿cómo podemos utilizarla para el bien y evitar que se convierta en una herramienta para el mal?
Aunque la prisa por hacer algo frente a la IA puede parecer nueva, en realidad no es más que la continuación de una conversación que dura ya años sobre las consecuencias no deseadas y los perjuicios de los algoritmos.
Por JANE C. HU
Las expectativas eran altas en la última audiencia sobre inteligencia artificial (IA) que tuvo lugar en el Congreso de Estados Unidos. “Desde el lanzamiento de ChatGPT hace poco más de un año, está claro que la inteligencia artificial podría transformar pronto casi todas las facetas de nuestra economía”, dijo la representante Nancy Mace, presidenta del Subcomité de Ciberseguridad, Tecnologías de la Información e Innovación Gubernamental de la Cámara de Representantes del Congreso de Estados Unidos. “El genio de la inteligencia artificial ya salió de la lámpara y no se puede volver a meter”.
Es una comparación acertada. La inteligencia artificial parece un genio: la tecnología es nueva y misteriosa, no sabemos exactamente cómo funciona y sabemos que es muy poderosa. También nos da miedo: en una encuesta realizada en el verano de 2023, más de la mitad de los estadounidenses declararon estar más preocupados que entusiasmados con la inteligencia artificial; se especula mucho sobre los efectos que tendrá esta tecnología en la economía, los trabajos, el sistema educativo y el arte; los líderes en tecnología han advertido que esta tecnología pone en peligro el destino de la humanidad. Parece que no se puede detener a la inteligencia artificial, así que la pregunta es: ¿cómo podemos utilizarla para el bien y evitar que se convierta en una herramienta para el mal?
Aunque la prisa por hacer algo frente a la IA puede parecer nueva, en realidad no es más que la continuación de una conversación que dura ya años sobre las consecuencias no deseadas y los daños causados por los algoritmos. La inteligencia artificial no es más que el último “genio” que no vuelve a la lámpara, el nuevo punto sin vuelta atrás tecnológico.
Ha habido muchos otros. En 2021, el genio fueron los algoritmos utilizados por las plataformas de redes sociales como Facebook, que han acelerado la polarización y la propagación de información errónea y malintencionada que amenaza la democracia. En 2019, el genio fue el algoritmo de la aplicación de mapas de Waze, que causaba más tráfico por las calles de los barrios que por avenidas. En 2016, el algoritmo de Facebook desató el “genio de las fake news”. En 2015, fueron las empresas financieras las que utilizaron big data para recortar los límites de crédito. Y, en 2011, Twitter fue el “genio tecnológico”, creando nuevos desafíos a la libertad de expresión. “Salvo que se tomen medidas extremas como bloquear por completo el acceso a las plataformas de comunicación abiertas y a las tecnologías digitales, los gobiernos tendrán que asumir que el encanto de la Era de la Información es también su maldición: la información va a fluir” escribió Adam Thierer, columnista de Forbes.
Estas conversaciones han dado forma a nuestro diálogo público y a nuestra comprensión sobre la privacidad de los datos y el papel que desempeñan los algoritmos en nuestra vida cotidiana. Pensemos en hace 10 años: ¿hasta qué punto pensábamos en lo que se mostraba en redes sociales o en a quién vendía Facebook nuestra información? Hoy en día, es bien sabido que lo que vemos en internet está determinado por algoritmos, y que la privacidad digital es prácticamente imposible. Incluso hay cuentas enteras de TikTok dedicadas a demostrar lo fácil que es encontrar cualquier cosa sobre casi cualquier persona. Pero la última década ha estado plagada de ejemplos de cómo los algoritmos nos perjudican: nos roban la atención, perpetúan las desigualdades sobre quién obtiene una hipoteca, quién puede optar por la libertad condicional, quién consigue una entrevista de trabajo o quién recibe diagnósticos médicos precisos, y amplifican la desinformación. Es en este entorno en el que llegó la inteligencia artificial generativa como ChatGPT.
Para Corynne McSherry, directora jurídica de Electronic Frontier Foundation (EFF), el pánico a la inteligencia artificial recuerda al Día de la Marmota. “Replica la ansiedad que hemos visto en torno a las redes sociales durante mucho tiempo”, afirma. Y, hasta ahora, parece el camino que se está siguiendo es el mismo camino que con la regulación de las redes sociales. Como dice McSherry: “Alguien en el Congreso lleva a un grupo de ejecutivos a Washington DC para que testifiquen sobre cómo ellos mismos deben ser regulados”.
En septiembre del 2023, el grupo de trabajo sobre IA del Senado de Estados Unidos invitó a un grupo de directivos de empresas de tecnología para debatir la regulación. Entre ellos estaban Sam Altman, de OpenAI, desarrollador de ChatGPT; Clément Delangue, de Hugging Face; Sundar Pichai de Google; Satya Nadella, de Microsoft; Elon Musk, de Twitter (o X si prefieren, pero yo no lo haré); Arvind Krishna, de IBM, y Mark Zuckerberg, de Meta. Muchas de estas personas y empresas llevan años acudiendo a Washington. El CEO de Facebook, Mark Zuckerberg, se enfrentó por primera vez al Congreso cuando Facebook se vio envuelto en el juicio de Cambridge Analytica en 2018. Dos años después, compareció con el fundador de Twitter Jack Dorsey, y de nuevo con Dorsey y el CEO de Google Sundar Pichai al año siguiente, en una audiencia sobre el papel de las redes sociales en la promoción del extremismo y la desinformación.
Otros expertos han testificado ante el Congreso de Estados Unidos sobre la necesidad de mayor regulación. Hubo una audiencia de la Comisión Federal de Comercio de Estados Unidos en 2019 sobre la protección de la privacidad de los datos de los consumidores, seguida de una audiencia del Senado en 2020, una audiencia de la Cámara de Representantes sobre la tecnología de reconocimiento facial en 2019 y, en 2021, el testimonio de la denunciante de Facebook Frances Haugen en una audiencia del Senado sobre las prácticas comerciales de Facebook, especialmente en lo que respecta a la privacidad de los niños. Nunca faltó, después de cada una de estas audiencias, algún legislador citado en las noticias diciendo que las audiencias ofrecían nuevas pruebas de la necesidad de regulaciones federales para proteger a los consumidores, y a la democracia, de los impactos de estas tecnologías.
Años después, un puñado de estados y ciudades en Estados Unidos han adoptado o considerado políticas que abordan aspectos concretos de la regulación de algoritmos, como la prohibición de la tecnología de reconocimiento facial o la propuesta de derechos de los consumidores a la privacidad de los datos, pero aún no existe una normativa federal exhaustiva sobre estas cuestiones. Ha habido intentos. En 2019, tres representantes estadounidenses presentaron la Algorithmic Accountability Act (Ley de Responsabilidad Algorítmica), que se perdió en un subcomité del Congreso. Se volvió a presentar en 2022 aunque de nuevo no llegó a ninguna parte, y luego se volvió a presentar en 2023. La trayectoria de ese proyecto de ley es una buena metáfora del progreso de la regulación tecnológica en general: cada versión del proyecto de ley es más profunda, más específica sobre lo que exige a las empresas que regula, y asigna responsabilidades más detalladas a agencias de gobierno específicas.
El presidente Joe Biden ha intentado sortear esta falta de avances mediante órdenes ejecutivas. En octubre de 2022 emitió una orden sobre privacidad de datos que limitaba la vigilancia de datos del gobierno de Estados Unidos sobre los ciudadanos europeos, pero no llegó a tomar ninguna medida que implicara a las empresas tecnológicas. Un año más tarde, en octubre 2023, Biden emitió otra orden ejecutiva, esta vez con directrices vagas para frenar los sesgos de la IA, pero aportó poco en términos de políticas concretas. Si su orden ejecutiva de 2022 nos da alguna pista de la rapidez con la que estas órdenes conducen al cambio, todavía tendremos que esperar bastante tiempo: establecer un grupo de jueces para formar un tribunal especial creado por Biden en su orden de 2022 demoró más de un año.
¿Cuál es el problema? Bueno, es complicado, y también lo es la tecnología en cuestión, lo que complica aún más las cosas. En los últimos años, hemos visto los límites de la comprensión de algunos legisladores y otras autoridades gubernamentales incluso sobre los conceptos tecnológicos más básicos, como el hecho de que el modelo de negocio de Facebook se basa en la venta de anuncios, o cómo funcionan los enlaces de Twitter. La falta de conocimientos básicos sobre tecnología suele ir acompañada de una falta de interés y, en ese vacío, otros problemas urgentes pasan a primer plano.
Legisladores interesados en la regulación también compiten con otra fuerza poderosa: el dinero. En 2022, Apple, Google, Microsoft, Meta y Amazon gastaron $69 millones de dólares en cabildeo o lobbying, lo que algunos legisladores han señalado como la principal razón por la que los proyectos de regulación tecnológica se han estancado en los últimos años. Una investigación de The New York Times también reveló que varios miembros del Congreso tienen posibles conflictos de interés con sus nombramientos en comisiones del Congreso y su propiedad de acciones tecnológicas.
Además de la influencia directa del capital, los ideales más elevados del capitalismo también han chocado con la idea de la regulación. La competencia global y la “innovación” se han citado constantemente como razones para evitar la regulación de empresas tecnológicas. En una audiencia en 2021, por ejemplo, Chris Coons, senador del estado de Delaware, dijo que estaba bien que los algoritmos de las empresas tecnológicas estuvieran diseñados para mantener a los usuarios pegados a sus plataformas. “No queremos limitar innecesariamente a algunas de las empresas más innovadoras y de mayor crecimiento de Occidente”, dijo. “Encontrar ese equilibrio va a requerir más conversación”.
Hasta ahora, gran parte de esa conversación ha tenido que ver, como era de esperarse, con las propias empresas tecnológicas. “La industria ha sido capaz de capturar muchas de esas conversaciones y hacerse con el control”, afirma Safiya Noble, directora del Center on Race and Digital Justice en la Universidad de California en Los Ángeles y autora del libro Algorithms of opressions: How search engines reinforce racism. Después de años insistiendo en que la industria tecnológica no podía ser regulada, que iba a perjudicar la competitividad o frenar la innovación, la industria ha conseguido solicitar políticas que le sean favorables a ella y a su crecimiento desenfrenado”.
Además, muchos aspectos de estas tecnologías las hacen “realmente difíciles de regular”, afirma Ben Winters, asesor jurídico del Electronic Privacy Information Center, una organización de la sociedad civil dedicada a la investigación de la privacidad digital. Por ejemplo, regular la capacidad de la inteligencia artificial para generar texto, imágenes, música u otra información podría ser inconstitucional, dadas las protecciones de la Primera Enmienda de la constitución de Estados Unidos que garantiza la libertad de expresión. Algunos han propuesto que las empresas sean responsables de los resultados de sus algoritmos, pero no está claro dónde empieza y termina exactamente la responsabilidad de una empresa por la información difundida en sus plataformas, y podría tener efectos terribles para la libertad de expresión en línea. La cuestión de la responsabilidad se complica aún más cuando se trata de algoritmos que funcionan como una “caja negra”: muchos ingenieros que ayudaron a formar a la tecnología no pueden saber exactamente por qué el sistema que construyeron acaba comportándose de una manera u otra.
Hay otras áreas grises que son difíciles de navegar, como qué tipos de datos en línea son permitidos para el algoritmo y qué tipo de consentimiento, si lo hay, deben buscar las empresas. En 2019 informé sobre un caso en el que investigadores usaron videos de YouTube disponibles públicamente para entrenar un modelo para adivinar cómo es una persona, y uno de los participantes involuntarios se sorprendió al enterarse de que había sido parte del experimento de enteramiento del modelo. Técnicamente no es ilegal, pero tampoco parece ético. Las dudas sobre la privacidad de los datos en línea “encajan con la falta de protección de la privacidad que todavía no tenemos”, dice Winters.
Y esa es la cosa con la IA: aumenta la importancia social de estos problemas sin resolver en torno a la privacidad y los algoritmos, y añade potencia informática a los sistemas que perpetúan la pérdida de privacidad y los prejuicios. En el pasado, los modelos más primitivos se entrenaban en conjuntos de datos más pequeños y requerían un entrenamiento considerable para llegar a ser medianamente competentes. Los grandes modelos lingüísticos que impulsan la inteligencia artificial son mucho más ágiles: han absorbido una enorme cantidad de datos y son capaces de realizar tareas para las que no fueron entrenados explícitamente. Como resultado, la “caja negra” del algoritmo se hace cada vez más profunda y oscura, resulta más difícil averiguar por qué, exactamente, un modelo escupe una respuesta, y potencialmente, con ello, abordar los problemas que plantea.
Al mismo tiempo, los usuarios de estos modelos necesitan menos conocimientos que nunca para manejarlos. Los sistemas de inteligencia artificial generativa como ChatGPT son increíblemente accesibles para el público en general, pero esa mayor accesibilidad es un arma de doble filo. No hace mucho, para consultar un modelo había que aprender a programar o, cómo mínimo, saber cómo plantear correctamente la pregunta para que el modelo diera una respuesta. Los modelos que aceptaba solicitudes en texto plano no eran muy sofisticados, como SmarterChild, el chatbot que todos creíamos que era inteligencia artificial de vanguardia en la década de 2000. SmarterChild tenía respuestas listas para la mayoría de nuestras reacciones: “¿con esa boquita le das besos a tu mamá?” era su respuesta predeterminada si decías groserías. Compárese con la actualidad, donde cualquiera puede enviar consultas complejas a ChatGPT en lenguaje simple. La gente ahora juega con ChatGPT pidiéndole que cree una serie de imágenes que representan “más a Seattle”, o que escriba correos electrónicos que suenan cada vez más amenazadores, y luego publica sus resultados en TikTok.
Todo esto es inocuo, pero ya hemos empezado a ver lo que está en juego con un mayor acceso a estas potentes tecnologías: deepfakes creados para difundir desinformación o porno como venganza; “alucinaciones” de ChatGPT (un eufemismo para “mentiras”) que acusaban falsamente a personas de delitos y eran archivadas en causas judiciales; arte creado por la inteligencia artificial que refuerza estereotipos dañinos. A medida que la IA siga desarrollándose y cada vez más gente la utilice y confíe en ella sin cuestiona su ética o sus resultados, habrá más problemas.
¿Hacia dónde nos dirigimos? Hasta ahora la conversación se ha centrado en la regulación, ya que, como dijo la representante Mace, el genio no puede volverse a meter en la lámpara. Pero Noble cuestiona este supuesto. Las empresas tecnológicas, dice, parecen estar utilizando el mismo manual que las empresas petroleras utilizaron hace décadas. “Las palabras progreso, innovación, industria… todos estos conceptos de la promesa del progreso estadounidense, son bastantes similares a los que se refieren el petróleo y gas para mejorar nuestras vidas”, dice Noble. Al igual que la industria de los combustibles fósiles, las grandes tecnológicas impulsan las industrias extractivas y los abusos laborales que las acompañan, y producen una enorme cantidad de emisiones de carbono. Estas empresas, dice Noble, “se presentan como que están aquí para quedarse, que son positivas, que tienen futuro”, pero rechaza que su existencia sea inevitable. “Ya que extraen todo lo que pueden de nosotros como consumidores y utilizan todos nuestros recursos comunes, nuestras carreteras, nuestra gente más preparada, nuestra atención, y el tiempo que pasamos en nuestros dispositivos, tenemos motivos para rechazarlo”.
Aunque el futuro de la inteligencia artificial no sea inevitable, la propia tecnología y la industria que la sustenta no desaparecerán de la noche a la mañana. Parece improbable que se materialicen políticas globales en el futuro: la cuestión es lo bastante complicada como para que las soluciones no sean únicas. Tomemos, por ejemplo, la idea de mejorar la transparencia de los algoritmos o la inteligencia artificial mediante auditorías o evaluaciones de impacto. Le pedí a Winters detalles sobre cómo las empresas las estaban llevando a cabo: qué tipo de datos evalúan los evaluadores?, ¿quiénes son los evaluadores, personas que trabajan en una empresa o terceros? “No existe una definición universal; cada vez que se utiliza, significa algo diferente”, afirma Winters. “Si es valioso y útil para los consumidores… bueno, el diablo está en los detalles”.
Una buena evaluación de impacto podría explicar la lógica que subyace a un algoritmo, cómo y por qué se utiliza para complementar la toma de decisiones humana, e incluir vías de apelación para el público. Pero dada la variabilidad de los sistemas algorítmicos y los límites actuales de lo que el gobierno puede obligar a las empresas a revelar sobre sus tecnologías, no está claro cuánto nos dirían realmente esas auditorías o evaluaciones ni lo sólidas que serían sus conclusiones. (Como dice la organización Alogrithmic Justice Lague: ¿quién audita a los auditores?)
McSherry, de la EFF, sugiere que una forma de minimizar los daños algorítmicos sería centrarse en casos específicos de sesgo o abuso, y aprovechar las herramientas legales existentes para combatirlos. “Tenemos toda una red de leyes que se aplican a un daño que te preocupa, más que a la tecnología en sí”, dice McSherry. Los “deepfakes” pueden combatirse con leyes estatales sobre derechos de publicidad, que impidan a las personas utilizar imágenes ajenas sin su consentimiento. Las leyes sobre difamación también pueden utilizarse como defensa en casos en los que la identidad de una persona se ha utilizado de forma inapropiada, o en algunos tipos de desinformación. (“En realidad no estoy segura de qué ley se va a redactar para impedir la desinformación”, dice McSherry.) Las leyes de derechos de autor podrían aplicarse en los casos en que la inteligencia artificial se apropie de tu trabajo, las leyes de derechos civiles impiden teóricamente la discriminación si te niegan injustamente una vivienda o un empleo. Ninguna de estas leyes garantiza que se haga justicia, y son un paso más defensivo que proactivo, pero no dejan de ser herramientas.
Aunque la inteligencia artificial pueda causar estragos, McSherry ve un aspecto positivo en su reciente ascenso: la gente por fin presta atención. El miedo a que la inteligencia artificial se convierta en el día del juicio final ha dado mucho de que hablar, pero cuando todo el mundo se calme, quizá sea posible un cambio real. “¿Y si aprovechamos este momento para dedicar toda esa energía no a los daños especulativos, sino a los reales?”, dice Mc Sherry. “Si en 2024 conseguimos realmente el tipo de regulación y transparencia que necesitamos para los daños existentes, aceptaré cualquier tipo de exageración alrededor del tema.”
Este artículo es publicado gracias a la colaboración de Letras Libres con Future Tense, un proyecto de Slate, New America, y Arizona State University.