









Toda la economía de la suscripción y, en buena parte, aquello en lo que internet se ha convertido en los últimos años, se basa en una tecnología que se está desmoronando. Ahora qué.
Salvo algunos incorregibles idealistas, los lectores de periódicos hemos asumido que escogemos uno en concreto para que nos cuente hasta el último equívoco, traspiés o acto de mala fe del político al que detestamos, mientras nos mantiene acunados en una placentera ignorancia sobre los pecados que suceden dentro de nuestras fronteras, ideológicas o morales.
Sobre el lecho de esta autocensura selectiva se erigen los medios de comunicación de masas. El silencio del adversario sobre un asunto determinado es una oportunidad de negocio para el resto. Llámenlo democracia, o libre mercado. La teoría dice que, aunque algunos medios puedan apagar sus linternas al apuntarlas hacia determinados rincones de la realidad, mientras existan suficientes luces con intereses dispares, la prensa acabará cumpliendo (si acaso, colectivamente) con su cometido de controlar los excesos del poder.
Sin embargo, a veces, se da una superposición de intereses que provoca que ciertos temas, personajes o crímenes nunca salgan a la luz. Ángulos ciegos. Como en el famoso modelo del queso suizo, ciertas historias quedan atrapadas en la telaraña porque todos, absolutamente todos los medios, deciden cerrar los ojos al mismo tiempo.
Una de ellas es la de Denis Petrov.
Petrov es el creador de archive.today, una página inicialmente dedicada a preservar un internet arcaico en la que todo el conocimiento era libre. Dicho de otro modo, un saltador de muros de pago. Utilizarlo es tan sencillo como introducir la URL de un artículo o cualquier otro contenido protegido tras un paywall y esperar unos segundos.
Es un robo flagrante de propiedad intelectual, pero nunca se ha aireado en ninguna parte. Para la prensa, denunciarlo conllevaría exponer a su público la incómoda revelación de que su sistema es vulnerable. Es una Trampa 22 de manual.
Desde siempre, los periodistas nos hemos propuesto sacar del anonimato a cualquier ciudadano que se empeñase en vivir en las sombras, desde Thomas Pynchon a Mar de Marchis. Reuters dedicó años y recursos para agarrar de las solapas a Banksy y revelar al mundo que es un tipo llamado Robin Gunningham; lo mismo con el enigmático creador del Bitcoin, alias Satoshi Nakamoto, que desde el New York Times desnudaron hace poco señalando a Adam Back, un criptógrafo británico.
Pero de Petrov no hay nada, ni siquiera uno de esos manidos enfoques de “¿héroe o villano?”, porque para eso primero habría que explicar quién es y para qué sirve su diabólica creación.
La historia de archive.today
Todo lo que sabemos de Petrov es gracias a unos pocos individuos que buscan venganza personal.
El internet actual es voluble, dado que toda historia registrada es manipulable a posteriori. Un artículo erróneo o inconveniente puede ser eliminado, o puede ocultarse de Google, lo cual viene a ser lo mismo. El propósito de archive.today fue hacer de internet algo inmutable, tomar una instantánea de cualquier página a demanda en el momento en que fue subida a la red. Puede que contuviese material no permitido –en cualquiera de sus acepciones– o que, simplemente, fuera modificada posteriormente. Pero aunque la página muestre hoy al mundo otra versión, borrada o editada, la original permanece inalterada en los servidores de archive.today
El proyecto lleva funcionando desde 2012 y, aunque su función original era arqueológica, la habilidad de esta herramienta para saltarse el muro de pago de los medios antes de tomar la instantánea le proporcionó una utilidad nueva e imprevista.
La historia de archive.today guarda paralelismos con Sci-Hub, el repositorio de papers creado por la desarrolladora rusokazaja Alexandra Elbakyan en 2011. En su caso, fue una respuesta al elevado coste que las editoriales cobraban a los científicos por acceder a un conocimiento habitualmente financiado con fondos públicos. Como Sci-Hub y otros recursos de la época –como The Pirate Bay, la página que alojaba ilegalmente series y películas–, archive.today funciona bajo diferentes direcciones-espejo (*.ph, *.is, *.fo, *.li, *.md, *.vn) que van apareciendo y desapareciendo.
No es la única página a la que se le ocurrió una idea para sortear los muros de pago, aunque casi todas han desaparecido y los medios de comunicación han tenido un papel relevante en su denuncia y persecución, dado que claramente infringen las leyes de propiedad intelectual. Otro de los saltadores de paywalls más populares de los últimos años, 12ft.io (su lema era “enséñame un muro de diez pies y yo te mostraré una escalera de 12 pies”, para subir más alto y ver qué hay detrás) fue tumbado por la News Media Alliance, organización que agrupa a cientos de editores en EEUU y Canadá.
Sin embargo, archive.today sigue ahí.
Imposible de atrapar
La página tiene el mismo diseño desde que nació. Un fondo amarillo pálido y una letra paloseco que emanan un aroma a aquel internet que aún no había sido colonizado por Silicon Valley y donde la influencia soviética aún se notaba: ese mismo universo (en el que muchos nos criamos) de los foros o los bloqueadores de anuncios, donde la víctima más recurrente no era, como hoy, la verdad sino la propiedad intelectual.
Por tanto, no es sorprendente que cuando algunos empezaron a tirar del hilo para descubrir quién había tras archive.today surgiera un nombre ruso. Para dar con el administrador de la página hubo que llegar hasta el final de una confusa maraña. Inicialmente, la página había sido registrada en una dirección de Praga, pero el fundador parecía estar ubicado en Nueva York según Crunchbase.
Los perseguidores han ido cotejando pequeñas pistas que el esquivo Petrov –a todas luces, un alias– iba dejando aquí y allá. Comentarios en foros sobre Corea del Norte donde revelaba que archive.today almacenaba también contenido de aquel país, respuestas en el Tumblr que sirve de FAQ a la página donde revelaba que sus servidores estaban en Europa; uno de ellos era el que la empresa francesa OVH tenía en Estrasburgo y ardió en 2021.
Un rastreo más exhaustivo publicado en el foro StackExchange encontró rastros de su actividad en GitHub y LinkedIn, donde el misterioso creador de archive.today se logueaba usando otro nombre: Masha Rabinovich, conectado con el LinkedIn de un supuesto graduado en ingeniería por la Universidad Humboldt de Berlín.
Varias personas en los últimos años han convertido la búsqueda en su obsesión. Existen multitud de pistas cruzadas, en algunas aparece Petrov, en otras Rabinovich e incluso otros noms de plume digitales. A veces las pistas apuntan a una sola persona y otras a que puede haber un pequeño grupo.
En los últimos meses está sucediendo algo. Al otro lado del globo, alguien está logrando sacar a Petrov de sus casillas, forzándole a dar explicaciones en un mundo en el que todo movimiento deja un rastro.
Quién paga la fiesta
En términos informáticos, archive.today funciona así: por un lado, un robot se salta el muro de pago haciéndose pasar por un rastreador web (crawler) como los que usa Google y registra el contenido de la página. Por el otro, almacena el contenido. Para garantizar que siempre haya una copia de la página accesible, se guardan en varios servidores, los textos por triplicado y las imágenes por duplicado.
Según las estimaciones más recientes del propio Petrov, el entramado de páginas almacenadas en sus servidores superó en 2021 los 500 millones. Hoy la cifra será mucho mayor, debido a que la popularidad de archive.today se correlaciona con la adopción del paywall por parte de los medios de comunicación.
En diciembre de 2012, poco después de arrancar, Petrov almacenaba unos 10 terabytes de datos, lo que le suponía un coste de entre 150 y 300 euros mensuales. Más adelante, el misterioso creador fue revelando una actualización del coste de mantener la página viva: 2.000 euros al mes en 2014, 4.000 dólares en 2016.
En un ejercicio especulativo por mi parte, solo siguiendo la misma progresión de crecimiento que archive.today tuvo en sus primeros diez años de vida (de un 58% anual) hoy la información a almacenar en sus servidores podría rondar los seis petabytes o 6.000 TB. ¿Cuánto costaría mantener esto? Se admiten propuestas, lo mejor que he podido cotejar es una estimación de entre 90.000 y 110.000 euros al mes. O dicho de un modo más redondo: más de un millón de euros al año solo en infraestructura de almacenamiento. Al margen está la computación necesaria para hacer funcionar los navegadores que se encargan de rastrear y copiar las páginas web y, desde luego, sus necesidades, asumiendo que sea un trabajo a tiempo completo y pueda gestionarlo todo él solo.
Por supuesto, es plausible que Petrov haya trasladado sus servidores fuera de Europa para reducir estos costes. O haber colocado una gran cantidad del contenido en modo frío, un servicio de acceso infrecuente a ciertos datos (como AWS Glacier Deep Archive o similar) que sale más barato; aún así, seguirían siendo varios miles de euros al mes que alguien tiene que pagar de su bolsillo.
Hasta 2022 tenía anuncios, pero estos se esfumaron cuando las agencias de publicidad descubrieron que en archive.today había también almacenado mucho contenido adulto. También recibía donaciones vía PayPal, esta vía decayó coincidiendo con el estallido de la guerra de Ucrania –es fácil imaginar por qué esos fondos ya no llegaban allí– así que archive.today fue cambiando de método. Al principio Petrov recelaba del mundo cripto y buscaba alternativas de micropagos como BuyMeACoffee, aunque en alguna ocasión ha recurrido a Monero, un protocolo irrastreable y descentralizado de criptomonedas. Es un terreno escurridizo, en el último episodio archive.today solicitaba donaciones a través de un desarrollador de origen italiano llamado Glizzy. Mañana la solución será otra.
Solo rascando un poco en la superficie parece evidente que detrás de archive.today hay bastante más que un informático ocioso con una web pirata y una misión por preservar la pureza de internet. ¿Quién financia esto, cuál es el agujero real que está provocando, está el Kremlin por medio? Sin embargo, nada de esto ha merecido la atención de los medios, en casi ninguna parte y mucho menos en España, donde la única piratería que merece nuestra atención es la del fútbol, una maquinaria de interés convenientemente lubricada por La Liga.
No todo se atribuye a que archive.today ataque al corazón mismo de la subsistencia de los periódicos; también hay que reconocer que hallar el rastro de alguien como Petrov requiere de un tipo de investigación ajena a la que se estila hoy en los medios, aún anclada en el siglo XX, y periodistas que la lleven a cabo.
‘Paywall’ duro, ‘paywall’ blando
Los muros de pago saltan ante nuestro ojos con ese elegante barniz traslúcido en el mismo momento en que nuestra atención prende su mecha. Monetizan nuestra frustración por saber, nos conocen mejor que nuestras parejas y nos envían ofertas irresistibles basadas en el perfil que las cookies han trazado de nosotros… pero ah, en los mecanismos que desactivan todo este engranaje no hay nada tan sofisticado.
La tecnología que se utiliza para descerrajar el fruto del trabajo de todo un sector tiene más de 15 años y además muestra sus tripas cada vez que alguien introduce una nueva URL en archive.today para ver su contenido.

Pocos paywalls resisten el embate de la tecnología soviética de Petrov. ¡Pero algunos lo hacen! Señal de que sus responsables han invertido dinero en construir un artefacto capaz de preservar la información con la que comercian, su bien más preciado. Uno de ellos es The Information, especializado en periodismo tecnológico que publica mucho contenido insider de Silicon Valley. Su suscripción vale entre 399 y 999 dólares al año, por lo que tiene sentido que su muro de pago sea prácticamente indestructible. Otros ejemplos en los que los paywalls parecen resistir a los robots que manda archive.today son el Financial Times, Bloomberg, o el Wall Street Journal, por las mismas razones.
Se preguntarán por qué no todo el mundo despliega un muro infranqueable, si esa posibilidad existe.
A riesgo de explicarlo de forma que confunda a los lectores más profanos de Letras Libres y enfurezca a los expertos, esencialmente hay dos tipos de paywall. Los primeros, basados en el cliente o client-based, envían la información al ordenador del usuario, pero solo la desvelan una vez se ha identificado como suscriptor; los otros (server-based o basados en el servidor) no envían ni una sola coma al exterior, y solo cuando la identificación se produce transmiten la mandanga: son conocidos como muros duros, hard paywalls.
Las diferencias pueden parecer triviales, pero un factor explica la popularidad de los muros más porosos. Para ofrecerle la información cuando usted la busca, Google necesita leer e indexar el contenido de las páginas, por eso incentivan trabajar con muros porosos, ya que sus robots pueden cotejar el contenido del artículo antes de que el muro se despliegue. Es normal, los medios necesitan a los buscadores para que sus noticias encuentren potenciales lectores o suscriptores. Este tipo de muros están construidos con JavaScript, un software que les permite una mayor versatilidad: por ejemplo, identificar a qué usuarios mostrar o no una página, o introducir modelos que cuentan el número de artículos leídos mensualmente por esa IP antes de desplegar el paywall.
En general, cuanto más dependes de buscadores o redes sociales, más endeble debe ser tu muro de pago. Hace unos años, desde Silicon Valley obligaron a los medios a usar páginas optimizadas, que cargaran rápido, para ser leídas en móvil. Google creó las Accelerated Mobile Pages (AMP) y Facebook sus Instant Articles, versiones que contenían, digamos, más “agujeros”, para regocijo de los saltadores de paywalls. El propio modelo de negocio de los medios en internet les obliga a tener una brecha de vulnerabilidad por la que gente como Petrov entra sin llamar.
La némesis inesperada
Petrov ha permanecido durante casi 1quince5 años en su cueva digital, combinando periodos frenéticos de actividad –donde explicaba el funcionamiento técnico de archive.today o se preguntaba en voz alta si, igual que los medios hicieron con el covid-19 durante la pandemia, él estaba contribuyendo ahora a diseminar información probélica con su trabajo desactivando muros– con meses de silencio.
Un bloguero finlandés residente en Nueva Zelanda llamado Jani Patokallio lleva años buscando a la persona que se esconde tras el alias. En este caso, sus motivos contra archive.today parecen asociados al origen de su propia familia. El apellido Patokallio fue registrado en Finlandia –sí, esto es posible allí– por primera vez en 1944. Algunas publicaciones en internet han asociado la creación del nuevo apellido a un pasado oscuro, relacionado con la alianza entre suomis y nazis contra los soviets que concluyó tras la Guerra de Laponia, precisamente en 1944. El asunto, como supondrán, es delicado en el país nórdico y, según parece, la familia ha tratado de contrarrestar este tipo de acusaciones vertidas contra ellos.
Patokallio publicó, en 2023, un largo post en su blog personal con sus pesquisas acerca de la persona que había tras archive.today. Salvo para cuatro gatos –conmigo, cinco– la investigación pasó desapercibida. Sin embargo, a comienzos de 2026, Patokallio recibió un correo de Petrov. Le pedía que retirara aquel post, ya que algunos medios estaban usándolo para informar sobre su posible identidad o paradero. Se negó y pronto recibió otra misiva, nada amistosa, que concluía:
“Con un nombre tan noble y poco común, que, en represalia, podría utilizarse para bautizar un proyecto fraudulento o convertirse en sinónimo de una nueva categoría de porno con IA… si quieres hacer como si esto nunca hubiera pasado, borra tu antiguo artículo…”
Además, Petrov le amenazó con publicar una investigación OSINT (con datos abiertos) sobre su presunto abuelo nazi o crear con IA una aplicación de citas gays que llevara el nombre de su blog. A los pocos días, el blog de Patokallio empezó a recibir ataques informáticos (DDoS) para saturarlo y que se mostrara como inaccesible.
¿Qué había pasado para que Petrov, hasta entonces hierático, saliera hecho un basilisco?
Algo se estaba moviendo. Poco antes, en noviembre de 2025, el FBI envió a Tucows, la empresa donde archive.today había adquirido su dominio web, exigiéndoles “el nombre del cliente, dirección de servicio y dirección de facturación”, información al parecer relacionada con “una investigación penal federal”. Aunque Tucows, al parecer, accedió a cumplir con los federales, es difícil que esta vía lleve a algún sitio. Para cualquier hacker ruso, una investigación del FBI debería ser una medalla, pero todo aquel ruido provocó algo más que sí molestó a Petrov.
Recientemente, Wikipedia anunció que eliminaría 700.000 enlaces que redirigen a archive.today y, más allá del tráfico, aquí hay un asunto cultural. Para Petrov, que la Wikipedia enlace a su página en lugar de al periódico que publicó la información es una victoria. También una forma de rebeldía, de lucha contra Occidente y el destino de internet.
La máquina que todo lo lee
Cuando la News Media Alliance logró clausurar el saltador de muros 12ft.io, su creador, el informático Thomas Millar, se fue a trabajar a Anthropic, la empresa de IA que desarrolla, entre otras cosas, Claude. Fue un movimiento previsible. Cuando se les pregunta por un contenido concreto, cualquiera de los nuevos navegadores o agentes creados por estas empresas son capaces de saltarse los muros de forma rutinaria para encontrar las respuestas que el usuario demanda. Son, literalmente, invisibles para los prompts, como demostró esta investigación del Columbia Journalism Review. Por supuesto, tampoco es algo que los medios estén anunciando a bombo y platillo.
Frente a la hostilidad de The New York Times, que ha demandado a OpenAI por nutrirse de su contenido para elaborar sus respuestas, otros medios han anunciado acuerdos con el creador de ChatGPT: el grupo Prisa en España, Le Monde en Francia, The Guardian en Reino Unido, Vox Media en EE. UU o el grupo alemán Axel Springer.
Jessica Lessin, CEO de The Information, tiene una visión muy particular de estos pactos: “Ante la amenaza de demandas judiciales, están buscando acuerdos comerciales para eximir a [OpenAI] de la acusación de robo. Estos equivalen a llegar a un acuerdo extrajudicial. Las editoriales dispuestas a ceder de esta manera no solo están dejando de defender su propia propiedad intelectual, sino que también están cambiando su credibilidad, ganada con tanto esfuerzo, por un poco de dinero de unas empresas que, al mismo tiempo, las infravaloran y crean productos claramente destinados a sustituirlas”.
Los agentes IA no solo han creado sistemas para saltar los muros de pago, sino aplicaciones dedicadas que incluso prometen mejorar la experiencia de lectura. Surgen cada pocas semanas. Hace poco salió SMRY, una especie de archive supervitaminado que no solo ofrece el contenido de cualquier artículo cerrado, sino que (a cambio de 3 dólares al mes), promete “resúmenes con IA, texto a voz con 10 voces naturales, subrayados y anotaciones en 5 colores, exportación a Notion y Obsidian, y un chat de IA para hacer preguntas sobre cualquier artículo”, todo ello sin publicidad. Es fácil ofrecer estos servicios con ayuda de la IA y cuando la materia prima es siempre ajena. Para cubrirse las espaldas, SMRY incluye una parrafada legal diciendo que no se hace responsable de los robos de propiedad intelectual de terceras personas que está alentando.
Pero con algunos paywalls, SMRY y su IA de última generación simplemente no funcionan. En esos casos, la aplicación simplemente despliega un simpático botón que dice: “Prueba con archive.is”. Una muestra del reconocimiento que existe en el sector de los saltadores de muros hacia el pionero Petrov.
Sea cual sea la posición que adoptemos en este debate, podemos acordar que Petrov puede ser un granuja que intuyó antes que nadie la porosidad de las cajas fuertes, la existencia de archive puede ser un incordio, pero carece de la capacidad de escala que podría convertirlo en una amenaza para la supervivencia de los medios de comunicación. El verdadero problema es que los editores podrían arrancar todos los archives, pero no podrán detener el invierno.
Quizá sea una señal de lo que está por venir. En marzo, Xataka, veterano medio especializado en tecnología, anunció Xtra, una versión premium, es decir de pago, pero “libre de muros de pago”. A cambio, ofrecen otro tipo de servicios, más personalizados para sus clientes más fieles: newsletters, promociones o recomendaciones. La suscripción sobrevive, pero sin el muro de pago. Para que esto sea posible, el único recurso con que un medio puede comerciar es la confianza, el único muro que no puede ser franqueado.
La gallina del tráfico, desplumada
Cuando, a finales de 2019, El Mundo desplegó su muro de pago de forma pionera, muchos acogimos la llegada de los paywall al periodismo español con alborozo, precisamente porque prometían un cambio de modelo: el clickbait y los contenidos baratos quedarían fuera de la ecuación, porque las cabeceras estarían obligadas a diferenciarse con contenidos de máxima calidad si querían que alguien pagara por ellas. Esto llevaría a aquellos medios que apostaran por el paywall a reinvertir ese nuevo ingreso por suscripciones en mejorar su producto: retener el talento (periodistas, programadores, diseñadores) con salarios más altos, apostar por fotografía propia en lugar de agencias o stock, etc. Sin embargo, nada de esto ha llegado a suceder. En algunos aspectos se inició, pero la revolución quedó a medio hornear. Precisamente este mes, la plantilla de El Mundo se ponía en huelga de firmas porque llevan años sin una subida salarial.
Uno pensaría que, cuando algo pasa de ser gratuito (con toda su letra pequeña) a ser de pago, está cambiando cantidad por calidad. En lugar de millones de visitantes, habrá muchos menos, pero al pagar por el servicio lo harán sostenible. Pero milagrosamente, la introducción de los muros de pago en los principales medios españoles no conllevó una caída drástica de las audiencias, sino todo lo contrario. Después de varios años con el muro enhiesto frente a su portada, El Mundo anunció en enero de este año que había pulverizado “todos los registros históricos de lectura de la prensa digital en España”. En la acera de enfrente, El País publicaba que 2025 había sido “un año récord con el mayor crecimiento de lectores entre los grandes periódicos”.
En una industria que sigue confundiendo la visibilidad con el impacto, nadie quiso matar a la gallina del tráfico y prácticamente todos optaron por un modelo mixto, donde unas noticias de pago –las consideradas mollares, es decir: política, economía y opinión– conviven con el contenido soft en abierto para que las visitas no decaigan. El cambio de modelo no había provocado ninguna catarsis en la lógica fundamental de los medios, centrados antes y ahora en ofrecer píldoras de información de última hora de forma incremental.
Pese a diversificar sus ingresos gracias a las suscripciones, la mayor parte de los medios se hicieron necesariamente adictos a Google Discover. Al poco tiempo, las ofertas para suscribirse bajaron, desde los doce euros al mes iniciales hasta los 99 céntimos (o menos) que vemos ahora a menudo. Todos nos repetíamos que el periodismo había que pagarlo (¡no como en la década anterior!), pero el producto que se ofrecía a los lectores no se volvió sustancialmente diferente tras levantarse los muros de pago.
Paralelamente, el contenido promocional o de eventos ha ido creciendo, ya sea para amortiguar la caída del banner o para compensar la pérdida de ingresos, porque no es lo mismo vender un producto por una décima parte de su valor inicial.
Al mismo tiempo, hay que lidiar con las desventajas que ha traído cerrar los contenidos. Mientras lo más elaborado de un medio queda confinado tras el muro, la competencia campa a sus anchas con equivalentes low cost. No es que la desinformación, como proclama el Gobierno, haya aumentado, es que en muchos lugares ya es lo único que se percibe.
Otro lamento común entre muchos periodistas es la desaparición de su marca. Antes uno podía simplemente dejar que su trabajo hablara por él. Ahora, como el fruto de nuestra labor intelectual está habitualmente bajo un muro de pago, algunos se ven obligados a sobreactuar y multiplicar su presencia en otras plataformas para compensar la pérdida de relevancia. O simplemente, aceptar su progresiva desaparición pública.
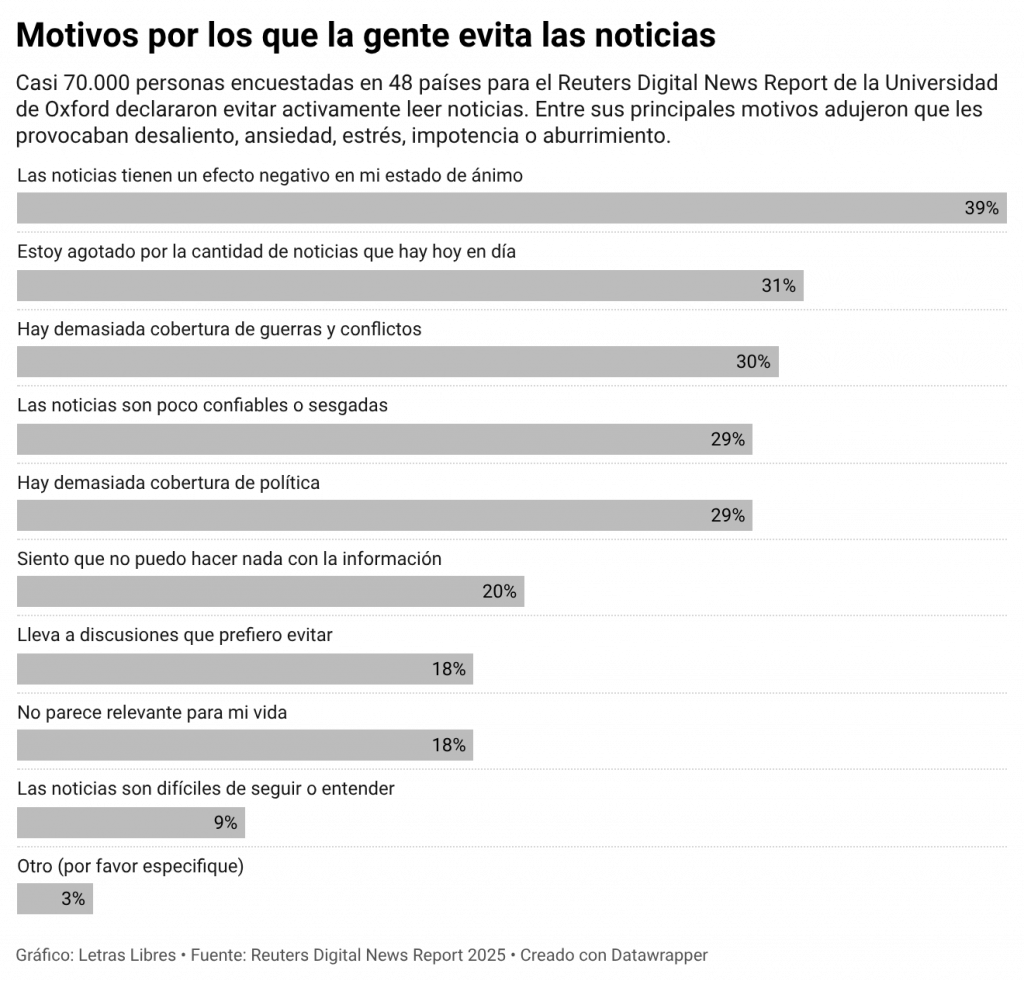
Es un problema circular que se va intensificando, porque como demuestran los informes que cada año publica el Instituto Reuters de la Universidad de Oxford, el público se va cansando de las noticias.
Quizás, la mayor consecuencia de la llegada de los muros de pago, es que cambió la dinámica de los medios de una forma imprevista.
Hace tan solo diez años, El País tenía un director como Antonio Caño que trataba de ampliar la base de lectores hacia el centro-derecha y El Mundo a David Jiménez haciendo lo propio en sentido contrario. Ahora parece un mal sueño para ambas cabeceras, pero sucedió. En aquel mundo, periódicos tradicionalmente enfrentados parecían correr incluso el riesgo de entenderse, de que algunas de sus posturas pudieran solaparse. No pasaba solo en España.
El Washington Post acaba de despedir a un tercio de su plantilla y muchos de sus mejores periodistas se están largando a la competencia. En un análisis sobre lo que esta debacle dice del presente de los medios, el periodista Derek Thompson (autor, junto a Ezra Klein, de Abundancia) explicaba que, durante el reinado de la publicidad como principal fuente de ingresos, los medios se veían obligados a ser neutrales (o al menos, a ser percibidos como tal) ya que esto incrementaba la confianza de los anunciantes. Hoy, donde todo pivota alrededor de las suscripciones, ya no se escribe buscando a todos los usuarios únicos posibles, sino tratando de engrosar una parroquia.
Lo que el paywall prometía era más calidad; lo que ha traído de verdad es más identidad. Los medios de comunicación más exitosos del siglo XXI son, según Thompson, “agresivos, quisquillosos, ideológicos y con una fuerte personalidad…” con tanta identidad que, “en muchos casos, se perciben como individuos”. De hecho, algunos individuos como Tucker Carlson son ya medios de comunicación de facto: su empresa, Tucker Carlson Network, emplea a unas 30 personas.
Y no solo eso, sino que además ya cuentan con las herramientas tecnológicas que lo permiten, léase Substack. Esta herramienta, por cierto, permite a los escritores escoger su propio “paywall”, incluyendo un muro duro ante el que Petrov no puede hacer nada.
En las últimas palabras que pueden encontrarse online, escritas el pasado 19 de marzo, el creador de archive.today parece amargado. Habla de la generación Substack. “Se muestran reacios a enlazar a medios antiguos”, dice, porque no pueden monetizarlo –a diferencia de cuando enlazan a otros Substack, en los que si el lector se suscribe ellos se llevan un porcentaje–. Los enlaces a páginas archivadas tampoco entran en la nueva economía de creadores. Los jóvenes que entran ahora en internet leen a toda una generación de creadores que crece al margen de la esfera de los medios tradicionales, y por tanto, también de su antimateria: los saltadores de paywalls.
Ha fantaseado tanto con la destrucción del sistema que erigía muros de pago por todas partes. Ha dedicado su vida a destruir todo lo que ha convertido a internet en el mejunje impersonal e implacable que es hoy, a recuperar aquella web de su juventud donde el conocimiento era libre. Pero un día Petrov se levantó, miró a su alrededor y se dio cuenta de que tampoco reconocía ya el paisaje contra el que lleva años conspirando.





